DataFrame 개념
DataFrame(데이터프레임)
DataFrame 개요
- 표(table-행렬) 를 다루는 Pandas의 타입.
- Database의 Table이나 Excel의 표와 동일한 역할을 한다.
- 분석할 데이터를 가지는 판다스의 가장 핵심적인 클래스이다.
- 행(row)와 열(column) 으로 구성되 있다.
-
각 행과 각 열은 식별자를 가지며 Series와 같이 두가지 종류가 있다.
- 순번
- 양수, 음수 index 두가지를 가진다.
- 컬럼도 내부적으로는 순번으고 관리되지만 우리가 조회할 때 사용할 수는 없다.
- 이름
- 명시적으로 지정한 행과 열의 이름을 말한다.
- 행의 이름은 index name 이라고 하고 열의 이름은 column name이라고 한다.
- index name과 column name은 중복될 수 있다.
- 명시적으로 지정하지 않으면 양수 순번이 index, column 이름으로 설정된다.
- 순번
- 하나의 행과 하나의 열은 Series로 구성된다.
- DataFrame 객체는 직접 데이터를 넣어 생성하거나 데이터 셋을 파일(csv, 엑셀, DB 등)로 부터 읽어와 생성한다.
DataFrame 생성
직접 생성
pd.DataFrame(data [, index=None, columns=None])- data
- DataFrame을 구성할 값을 설정
- Series, List, ndarray를 담은 2차원 배열
- 열이름을 key로 컬럼의 값 value로 하는 딕션어리(사전)
- DataFrame을 구성할 값을 설정
- index
- index명으로 사용할 값 배열로 설정
- columns
- 컬럼명으로 사용할 값 배열로 설정
- data
import os
import numpy as np
import pandas as pd
# 딕셔너리를 이용해 생성.
# key: 컬럼명, value: 그 컬럼의 값들을 1 차원 자료구조로 설정.
# value의 리스트의 크기는 같아야 한다.
dic = {
'id':['id-1', 'id-2', 'id-3', 'id-4', 'id-5'],
'korean':[100,50,70,60,90],
'english':[90,80,100,60,40]
}
grade = pd.DataFrame(dic)
print(grade)
grade # jupyter notebook 에서는 그냥 grade로 뽑는다.
id korean english
0 id-1 100 90
1 id-2 50 80
2 id-3 70 100
3 id-4 60 60
4 id-5 90 40
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
# 2차원 자료구조를 이용해서 생성
np.random.seed(0) # num파일 내 파일
data = np.random.randint(10, size=(5,3)) # 0 ~ 10-1 사이의 난수로 5행 3열의 행렬을 생성!!
# data_df = pd.DataFrame(data)
data_df = pd.DataFrame(data, columns=['AA', 'BB', 'CC'],
index=['가', '나', '다', '라', '마']) # 주의사항! colum과 index 설정시 행과 열의 개수를 일치하게 입력한다.
data_df
| AA | BB | CC | |
|---|---|---|---|
| 가 | 5 | 0 | 3 |
| 나 | 3 | 7 | 9 |
| 다 | 3 | 5 | 2 |
| 라 | 4 | 7 | 6 |
| 마 | 8 | 8 | 1 |
DataFrame의 객체를 파일에 저장
- DataFrame객체는 다양한 형식의 파일로 저장할 수 있다.
- 기본구문
DataFrame객체.to_파일타입()
CSV 파일로 저장
DataFrame객체.to_csv(파일경로,sep=',', index=True, header=True, encoding)- 텍스트 파일로 저장
- 파일경로: 저장할 파일경로(경로/파일명)
- sep : 데이터 구분자
- index, header: 인덱스/헤더 저장 여부
- encoding: 기본- UTF-8
- 만약 index를 True로 도출하면 0,1,2,3,4,…로 저장이 되기 때문에 보통 index=False로 한다.
- header는 columns 이다.
import os
os.getcwd()
'/Users/seokminlee/Desktop/mose/pandas_template/02_Pandas_DataFrame'
import os
# dataframe을 저장할 디렉토리 생성
os.makedirs('saved_data', exist_ok=True)
grade.to_csv('saved_data/grade1.csv')
grade.to_csv('saved_data/grade2.csv', index = False) # index이름은 저장안함.
grade.to_csv('saved_data/grade3.csv', index = False, header = False) # index/column 이름 저장안함.
grade.to_csv('saved_data/grade5.csv', sep='\t', index = False) #값 구분자로 tab 사용.
엑셀로 저장
DataFrame객체.to_excel(파일경로, index=True, header=True)
grade.to_excel('saved_data/grade1.xlsx', index = False)
- “!명령어” 는 터미널 명령어를 사용할때 사용한다.
# 엑셀 xls 확장자 쓰고 읽을떄 사용하는 모듈
!pip install xlwt xlrd
Requirement already satisfied: xlwt in /Users/seokminlee/opt/anaconda3/envs/ml/lib/python3.9/site-packages (1.3.0)
Requirement already satisfied: xlrd in /Users/seokminlee/opt/anaconda3/envs/ml/lib/python3.9/site-packages (2.0.1)
# 엑셀 xlsx 확장자 쓰고 읽을떄 사용하는 모듈
!pip install openpyxl
Requirement already satisfied: openpyxl in /Users/seokminlee/opt/anaconda3/envs/ml/lib/python3.9/site-packages (3.0.10)
Requirement already satisfied: et-xmlfile in /Users/seokminlee/opt/anaconda3/envs/ml/lib/python3.9/site-packages (from openpyxl) (1.1.0)
기타 형식
# pickle => binaru(bytes) 로 저장.
grade.to_pickle('saved_data/grade.pk1')
# html의 테이블로 저장
grade.to_html('saved_data/grade.html', index=False)
파일로 부터 데이터셋을 읽어와 생성하기
csv 파일 등 텍스트 파일로 부터 읽어와 생성
pd.read_csv(파일경로, sep=',', header, index_col, na_values, encoding)- 파일경로
- 읽어올 파일의 경로
- sep=”,”
- 데이터 구분자.
- 기본값: 쉼표
- header=정수
- 열이름(컬럼이름)으로 사용할 행 지정
- 기본값: 첫번째 행
- None을 설정하면 Header는 없다는 것으로 파일의 첫번째 행부터 값으로 사용하고 컬럼명은 0부터 자동증가하는 값을 붙인다.
- index_col=정수,컬럼명
- index 명으로 사용할 열이름(문자열)이나 열의 순번(정수)을 지정.
- 생략시 0부터 자동증가하는 값을 붙인다.
- na_values
- 읽어올 데이터셋의 값 중 결측치로 처리할 문자열 지정.
- 파일경로
#grade1.csv (index, header 모두 저장된 파일)
grade1 = pd.read_csv('saved_data/grade1.csv')
grade1
| Unnamed: 0 | id | korean | english | |
|---|---|---|---|---|
| 0 | 0 | id-1 | 100 | 90 |
| 1 | 1 | id-2 | 50 | 80 |
| 2 | 2 | id-3 | 70 | 100 |
| 3 | 3 | id-4 | 60 | 60 |
| 4 | 4 | id-5 | 90 | 40 |
grade1_2 = pd.read_csv('saved_data/grade1.csv',index_col=0) # 0번째에 있는 column을 index로 보낸 표
grade1_2
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
# index가 없이 저장한 csv파일
grade3= pd.read_csv('saved_data/grade2.csv',header = None,
names = ['아이디','국어','영어'])
grade3
| 아이디 | 국어 | 영어 | |
|---|---|---|---|
| 0 | id | korean | english |
| 1 | id-1 | 100 | 90 |
| 2 | id-2 | 50 | 80 |
| 3 | id-3 | 70 | 100 |
| 4 | id-4 | 60 | 60 |
| 5 | id-5 | 90 | 40 |
#index 명, column명 둘다 저장이 안된 파일
grade3 = pd.read_csv('saved_data/grade3.csv', header=None)
grade3
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
# sep = '\t' 로 저장한 파일
grade5 = pd.read_csv('saved_data/grade5.csv', sep='\t') # defaul 구분자:,
grade5
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
# 결측지가 저장된 파일
grade_na = pd.read_csv('saved_data/grade_na.csv', na_values='?') # '?'를 결측지로 바꾸는 명령어 ""na_values = '?' "
grade_na
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100.0 | 90.0 |
| 1 | id-2 | 50.0 | NaN |
| 2 | id-3 | NaN | 100.0 |
| 3 | id-4 | 60.0 | 60.0 |
| 4 | id-5 | 90.0 | 40.0 |
pd.read_csv?
na_values : scalar, str, list-like, or dict, optional
Additional strings to recognize as NA/NaN. If dict passed, specific
per-column NA values. By default the following values are interpreted as
NaN: '', '#N/A', '#N/A N/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan',
'1.#IND', '1.#QNAN', '<NA>', 'N/A', 'NA', 'NULL', 'NaN', 'n/a',
'nan', 'null'.
grade_na.isnull()
| id | korean | english | |
|---|---|---|---|
| 0 | False | False | False |
| 1 | False | False | False |
| 2 | False | False | False |
| 3 | False | False | False |
| 4 | False | False | False |
엑셀파일 읽기
grade_xlsx = pd.read_excel('saved_data/grade1.xlsx',index_col = 0)
grade_xlsx
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
grade_xls = pd.read_excel('saved_data/grade2.xls')
grade_xls
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
기타
grade_pk1 = pd.read_pickle('saved_data/grade.pk1')
grade_pk1
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
grade_html = pd.read_html('saved_data/grade.html')
type(grade_html) # html 파일안에 있는 모든 table들을 읽어서 list로 반환.
grade_html[0]
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
url = 'https://ko.wikipedia.org/wiki/FIFA_%EC%9B%94%EB%93%9C%EC%BB%B5'
world_cup = pd.read_html(url)
print(len(world_cup))
world_cup[1]
12
| 대륙별 지역 | 출전국 수 | 본선 진출국 수 | 본선 진출율 | |
|---|---|---|---|---|
| 0 | 아프리카(CAF) | 55 | 5 | 9% |
| 1 | 아시아(AFC) | 46 | 4.5 1 | 9.7% |
| 2 | 오세아니아(OFC) | 16 | 0.5 1 | 3% |
| 3 | 유럽(UEFA) | 53 | 13 | 24% |
| 4 | 북중미카리브(CONCACAF) | 40 | 3.5 1 | 8.7% |
| 5 | 남아메리카(CONMEBOL) | 10 | 4.5 1 | 45% |
| 6 | 개최국(대륙을 불문하고 선정됨.) | 1 | 1 | 100% |
| 7 | 총합 | 220 | 32 | 14.5% |
주요 메소드, 속성
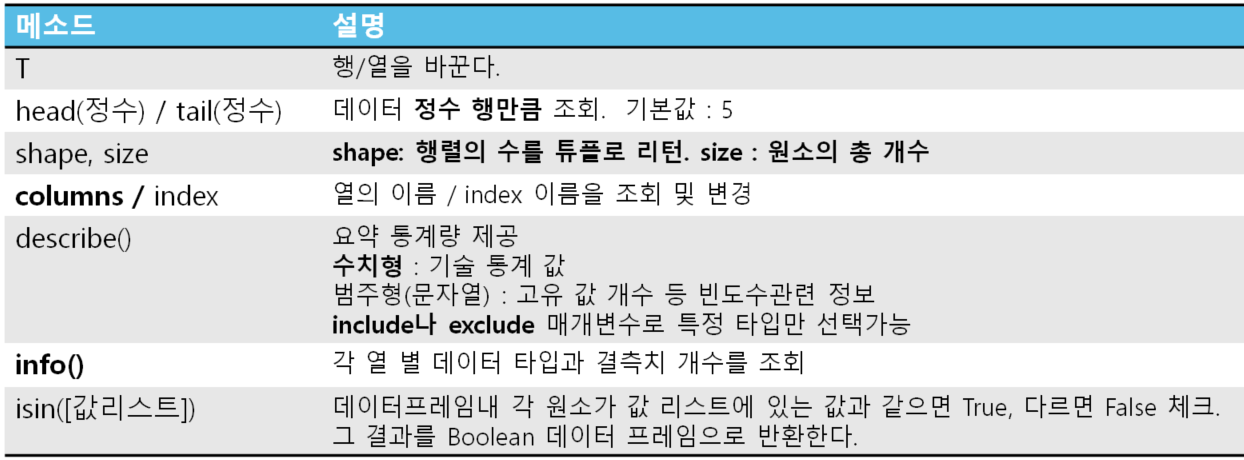
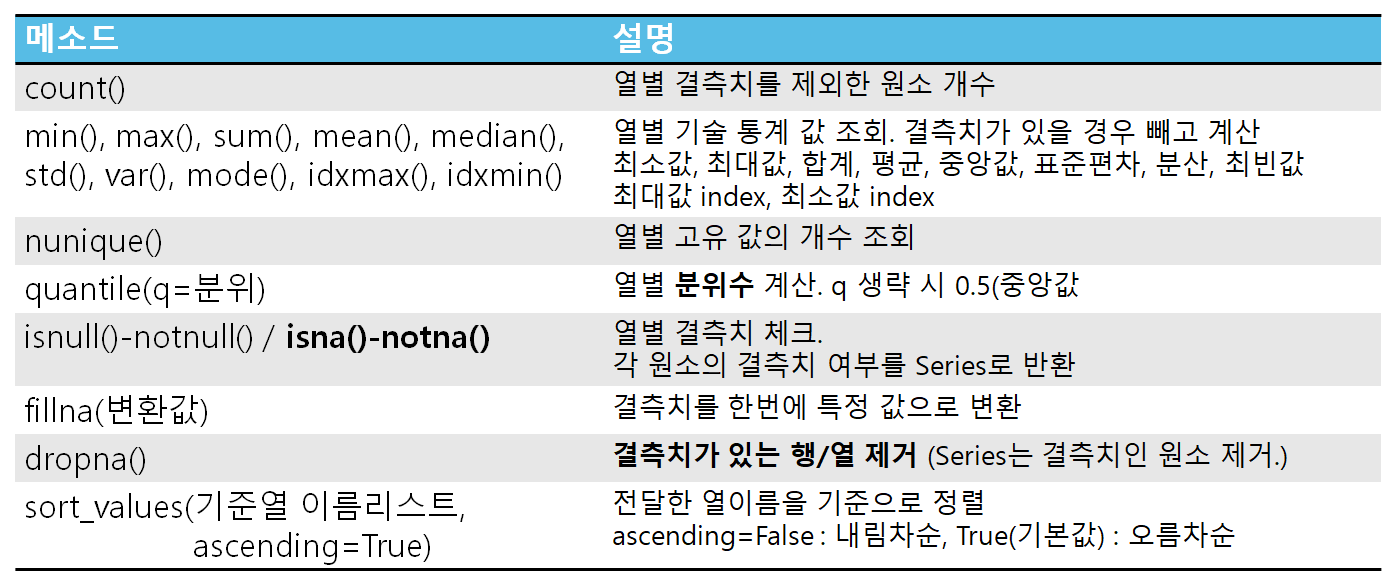
데이터 프레임의 기본 정보 조회
- csv 파일 읽기
- shape
- info()
- head()
- tail()
- isnull().sum()
- 컬럼별 null 체크 (sum() 한번 더 하면 총개수)
- describe() : 숫자형-기술통계값, 범주형-총개수, 고유값들, 최빈값
os.getcwd()
os.chdir('/Users/seokminlee/Desktop/mose/pandas_template') # + 현재 working directory 확인 후 경로 변경
import pandas as pd
# csv 파일을 읽어서 DataFrame 생성
df = pd.read_csv('data/movie.csv')
df.shape # 튜플 (행수, 열수) => DataFrame의 행/열의 개수
# (4916, 28) # 영화 4916편 정보, 각 영화는 28개의 속성
(4916, 28)
# dataframe.head([행수]), tail([행수]) : 앞/뒤에 지정한 행수만큼만 확인, default: 5행
# 데이터셋의 값들의 (열별) 구성을 확인. 컬럼값들이 어떻게 구성되있는지를 데이터 딕셔너리와 비교해서 확인.
# 참고: 데이터 딕셔너리-데이터셋에 대한 설명서
df.head() # 행기준 앞 5행
| color | director_name | num_critic_for_reviews | duration | director_facebook_likes | actor_3_facebook_likes | actor_2_name | actor_1_facebook_likes | gross | genres | ... | num_user_for_reviews | language | country | content_rating | budget | title_year | actor_2_facebook_likes | imdb_score | aspect_ratio | movie_facebook_likes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Color | James Cameron | 723.0 | 178.0 | 0.0 | 855.0 | Joel David Moore | 1000.0 | 760505847.0 | Action|Adventure|Fantasy|Sci-Fi | ... | 3054.0 | English | USA | PG-13 | 237000000.0 | 2009.0 | 936.0 | 7.9 | 1.78 | 33000 |
| 1 | Color | Gore Verbinski | 302.0 | 169.0 | 563.0 | 1000.0 | Orlando Bloom | 40000.0 | 309404152.0 | Action|Adventure|Fantasy | ... | 1238.0 | English | USA | PG-13 | 300000000.0 | 2007.0 | 5000.0 | 7.1 | 2.35 | 0 |
| 2 | Color | Sam Mendes | 602.0 | 148.0 | 0.0 | 161.0 | Rory Kinnear | 11000.0 | 200074175.0 | Action|Adventure|Thriller | ... | 994.0 | English | UK | PG-13 | 245000000.0 | 2015.0 | 393.0 | 6.8 | 2.35 | 85000 |
| 3 | Color | Christopher Nolan | 813.0 | 164.0 | 22000.0 | 23000.0 | Christian Bale | 27000.0 | 448130642.0 | Action|Thriller | ... | 2701.0 | English | USA | PG-13 | 250000000.0 | 2012.0 | 23000.0 | 8.5 | 2.35 | 164000 |
| 4 | NaN | Doug Walker | NaN | NaN | 131.0 | NaN | Rob Walker | 131.0 | NaN | Documentary | ... | NaN | NaN | NaN | NaN | NaN | NaN | 12.0 | 7.1 | NaN | 0 |
5 rows × 28 columns
df.tail() # 행기준 뒤 5행
| color | director_name | num_critic_for_reviews | duration | director_facebook_likes | actor_3_facebook_likes | actor_2_name | actor_1_facebook_likes | gross | genres | ... | num_user_for_reviews | language | country | content_rating | budget | title_year | actor_2_facebook_likes | imdb_score | aspect_ratio | movie_facebook_likes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4911 | Color | Scott Smith | 1.0 | 87.0 | 2.0 | 318.0 | Daphne Zuniga | 637.0 | NaN | Comedy|Drama | ... | 6.0 | English | Canada | NaN | NaN | 2013.0 | 470.0 | 7.7 | NaN | 84 |
| 4912 | Color | NaN | 43.0 | 43.0 | NaN | 319.0 | Valorie Curry | 841.0 | NaN | Crime|Drama|Mystery|Thriller | ... | 359.0 | English | USA | TV-14 | NaN | NaN | 593.0 | 7.5 | 16.00 | 32000 |
| 4913 | Color | Benjamin Roberds | 13.0 | 76.0 | 0.0 | 0.0 | Maxwell Moody | 0.0 | NaN | Drama|Horror|Thriller | ... | 3.0 | English | USA | NaN | 1400.0 | 2013.0 | 0.0 | 6.3 | NaN | 16 |
| 4914 | Color | Daniel Hsia | 14.0 | 100.0 | 0.0 | 489.0 | Daniel Henney | 946.0 | 10443.0 | Comedy|Drama|Romance | ... | 9.0 | English | USA | PG-13 | NaN | 2012.0 | 719.0 | 6.3 | 2.35 | 660 |
| 4915 | Color | Jon Gunn | 43.0 | 90.0 | 16.0 | 16.0 | Brian Herzlinger | 86.0 | 85222.0 | Documentary | ... | 84.0 | English | USA | PG | 1100.0 | 2004.0 | 23.0 | 6.6 | 1.85 | 456 |
5 rows × 28 columns
# DataFrame 자체의 정보 => 행/열
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4916 entries, 0 to 4915
Data columns (total 28 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 color 4897 non-null object
1 director_name 4814 non-null object
2 num_critic_for_reviews 4867 non-null float64
3 duration 4901 non-null float64
4 director_facebook_likes 4814 non-null float64
5 actor_3_facebook_likes 4893 non-null float64
6 actor_2_name 4903 non-null object
7 actor_1_facebook_likes 4909 non-null float64
8 gross 4054 non-null float64
9 genres 4916 non-null object
10 actor_1_name 4909 non-null object
11 movie_title 4916 non-null object
12 num_voted_users 4916 non-null int64
13 cast_total_facebook_likes 4916 non-null int64
14 actor_3_name 4893 non-null object
15 facenumber_in_poster 4903 non-null float64
16 plot_keywords 4764 non-null object
17 movie_imdb_link 4916 non-null object
18 num_user_for_reviews 4895 non-null float64
19 language 4904 non-null object
20 country 4911 non-null object
21 content_rating 4616 non-null object
22 budget 4432 non-null float64
23 title_year 4810 non-null float64
24 actor_2_facebook_likes 4903 non-null float64
25 imdb_score 4916 non-null float64
26 aspect_ratio 4590 non-null float64
27 movie_facebook_likes 4916 non-null int64
dtypes: float64(13), int64(3), object(12)
memory usage: 1.1+ MB
DataFrame 정보 읽는법.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4916 entries, 0 to 4915 ==================> 행 정보, 행수, index dlfma
Data columns (total 28 columns): ==================> 열 정보
# Column Non-Null Count Dtype =====> 개별 컬럼 정보: 컬롬이름, 결측치제외한 데이터개수, 타입
--- ------ -------------- -----
0 color 4897 non-null object
1 director_name 4814 non-null object
2 num_critic_for_reviews 4867 non-null float64
3 duration 4901 non-null float64
4 director_facebook_likes 4814 non-null float64
5 actor_3_facebook_likes 4893 non-null float64
6 actor_2_name 4903 non-null object
7 actor_1_facebook_likes 4909 non-null float64
8 gross 4054 non-null float64
9 genres 4916 non-null object
--- ------ -------------- -----
26 aspect_ratio 4590 non-null float64
27 movie_facebook_likes 4916 non-null int64
dtypes: float64(13), int64(3), object(12) ===============> 데이터 타입별 컬럼개수.
memory usage: 1.1+ MB ===============> 메모리 크기.
- object: 문자열
- 컴럼별로
- 결측치 있는 지 여부
- 데이터 타입, 크기 확인 – 금액인데 oject로 있는경우 들 확인필요.
- 데이터 딕셔너리와 비교해서 잘못된 데이터 타입은 없는지 확인.
- 컬럼이 가지는 값에 비해 너무 큰 크기로 잡힌 것은 아닌지 확인.
# 결측치 개수를 확인 => 컬럼별.
# df.isnull() #원소별로 결측치인지 여부 확인: True- 결측치, False: 일반값
# df.isnull().sum()
# 1. bool 값들을 sum()- 덧셈 : True - 1, False - 0 ==> True가 몇개?
# 2. DataFrame객체.sum() - 컬럼단위로 계산.
df.isna().sum()
color 19
director_name 102
num_critic_for_reviews 49
duration 15
director_facebook_likes 102
actor_3_facebook_likes 23
actor_2_name 13
actor_1_facebook_likes 7
gross 862
genres 0
actor_1_name 7
movie_title 0
num_voted_users 0
cast_total_facebook_likes 0
actor_3_name 23
facenumber_in_poster 13
plot_keywords 152
movie_imdb_link 0
num_user_for_reviews 21
language 12
country 5
content_rating 300
budget 484
title_year 106
actor_2_facebook_likes 13
imdb_score 0
aspect_ratio 326
movie_facebook_likes 0
dtype: int64
df.describe()
# 1. 컬럼단위로 통계치를 묶어서 보여준다.
# 2. 수치형 컬럼들만 보여준다.
| num_critic_for_reviews | duration | director_facebook_likes | actor_3_facebook_likes | actor_1_facebook_likes | gross | num_voted_users | cast_total_facebook_likes | facenumber_in_poster | num_user_for_reviews | budget | title_year | actor_2_facebook_likes | imdb_score | aspect_ratio | movie_facebook_likes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4867.000000 | 4901.000000 | 4814.000000 | 4893.000000 | 4909.000000 | 4.054000e+03 | 4.916000e+03 | 4916.000000 | 4903.000000 | 4895.000000 | 4.432000e+03 | 4810.000000 | 4903.000000 | 4916.000000 | 4590.000000 | 4916.000000 |
| mean | 137.988905 | 107.090798 | 691.014541 | 631.276313 | 6494.488491 | 4.764451e+07 | 8.264492e+04 | 9579.815907 | 1.377320 | 267.668846 | 3.654749e+07 | 2002.447609 | 1621.923516 | 6.437429 | 2.222349 | 7348.294142 |
| std | 120.239379 | 25.286015 | 2832.954125 | 1625.874802 | 15106.986884 | 6.737255e+07 | 1.383222e+05 | 18164.316990 | 2.023826 | 372.934839 | 1.002427e+08 | 12.453977 | 4011.299523 | 1.127802 | 1.402940 | 19206.016458 |
| min | 1.000000 | 7.000000 | 0.000000 | 0.000000 | 0.000000 | 1.620000e+02 | 5.000000e+00 | 0.000000 | 0.000000 | 1.000000 | 2.180000e+02 | 1916.000000 | 0.000000 | 1.600000 | 1.180000 | 0.000000 |
| 25% | 49.000000 | 93.000000 | 7.000000 | 132.000000 | 607.000000 | 5.019656e+06 | 8.361750e+03 | 1394.750000 | 0.000000 | 64.000000 | 6.000000e+06 | 1999.000000 | 277.000000 | 5.800000 | 1.850000 | 0.000000 |
| 50% | 108.000000 | 103.000000 | 48.000000 | 366.000000 | 982.000000 | 2.504396e+07 | 3.313250e+04 | 3049.000000 | 1.000000 | 153.000000 | 1.985000e+07 | 2005.000000 | 593.000000 | 6.600000 | 2.350000 | 159.000000 |
| 75% | 191.000000 | 118.000000 | 189.750000 | 633.000000 | 11000.000000 | 6.110841e+07 | 9.377275e+04 | 13616.750000 | 2.000000 | 320.500000 | 4.300000e+07 | 2011.000000 | 912.000000 | 7.200000 | 2.350000 | 2000.000000 |
| max | 813.000000 | 511.000000 | 23000.000000 | 23000.000000 | 640000.000000 | 7.605058e+08 | 1.689764e+06 | 656730.000000 | 43.000000 | 5060.000000 | 4.200000e+09 | 2016.000000 | 137000.000000 | 9.500000 | 16.000000 | 349000.000000 |
df.describe(include=['object'])
# 결츨치가 아닌 개수,
#컬러인지 아닌지,
# 컬러가 4693
| color | director_name | actor_2_name | genres | actor_1_name | movie_title | actor_3_name | plot_keywords | movie_imdb_link | language | country | content_rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4897 | 4814 | 4903 | 4916 | 4909 | 4916 | 4893 | 4764 | 4916 | 4904 | 4911 | 4616 |
| unique | 2 | 2397 | 3030 | 914 | 2095 | 4916 | 3519 | 4756 | 4916 | 47 | 65 | 18 |
| top | Color | Steven Spielberg | Morgan Freeman | Drama | Robert De Niro | Avatar | Steve Coogan | based on novel | http://www.imdb.com/title/tt0499549/?ref_=fn_t... | English | USA | R |
| freq | 4693 | 26 | 18 | 233 | 48 | 1 | 8 | 4 | 1 | 4582 | 3710 | 2067 |
df.describe(include=['int32', 'float64']) #int32, float64 를 포함한 타입의 컬럼.
| num_critic_for_reviews | duration | director_facebook_likes | actor_3_facebook_likes | actor_1_facebook_likes | gross | facenumber_in_poster | num_user_for_reviews | budget | title_year | actor_2_facebook_likes | imdb_score | aspect_ratio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4867.000000 | 4901.000000 | 4814.000000 | 4893.000000 | 4909.000000 | 4.054000e+03 | 4903.000000 | 4895.000000 | 4.432000e+03 | 4810.000000 | 4903.000000 | 4916.000000 | 4590.000000 |
| mean | 137.988905 | 107.090798 | 691.014541 | 631.276313 | 6494.488491 | 4.764451e+07 | 1.377320 | 267.668846 | 3.654749e+07 | 2002.447609 | 1621.923516 | 6.437429 | 2.222349 |
| std | 120.239379 | 25.286015 | 2832.954125 | 1625.874802 | 15106.986884 | 6.737255e+07 | 2.023826 | 372.934839 | 1.002427e+08 | 12.453977 | 4011.299523 | 1.127802 | 1.402940 |
| min | 1.000000 | 7.000000 | 0.000000 | 0.000000 | 0.000000 | 1.620000e+02 | 0.000000 | 1.000000 | 2.180000e+02 | 1916.000000 | 0.000000 | 1.600000 | 1.180000 |
| 25% | 49.000000 | 93.000000 | 7.000000 | 132.000000 | 607.000000 | 5.019656e+06 | 0.000000 | 64.000000 | 6.000000e+06 | 1999.000000 | 277.000000 | 5.800000 | 1.850000 |
| 50% | 108.000000 | 103.000000 | 48.000000 | 366.000000 | 982.000000 | 2.504396e+07 | 1.000000 | 153.000000 | 1.985000e+07 | 2005.000000 | 593.000000 | 6.600000 | 2.350000 |
| 75% | 191.000000 | 118.000000 | 189.750000 | 633.000000 | 11000.000000 | 6.110841e+07 | 2.000000 | 320.500000 | 4.300000e+07 | 2011.000000 | 912.000000 | 7.200000 | 2.350000 |
| max | 813.000000 | 511.000000 | 23000.000000 | 23000.000000 | 640000.000000 | 7.605058e+08 | 43.000000 | 5060.000000 | 4.200000e+09 | 2016.000000 | 137000.000000 | 9.500000 | 16.000000 |
df.describe(exclude=['float64']) #float64 를뺴고 나머지 타입의 컬럼.
| color | director_name | actor_2_name | genres | actor_1_name | movie_title | num_voted_users | cast_total_facebook_likes | actor_3_name | plot_keywords | movie_imdb_link | language | country | content_rating | movie_facebook_likes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4897 | 4814 | 4903 | 4916 | 4909 | 4916 | 4.916000e+03 | 4916.000000 | 4893 | 4764 | 4916 | 4904 | 4911 | 4616 | 4916.000000 |
| unique | 2 | 2397 | 3030 | 914 | 2095 | 4916 | NaN | NaN | 3519 | 4756 | 4916 | 47 | 65 | 18 | NaN |
| top | Color | Steven Spielberg | Morgan Freeman | Drama | Robert De Niro | Avatar | NaN | NaN | Steve Coogan | based on novel | http://www.imdb.com/title/tt0499549/?ref_=fn_t... | English | USA | R | NaN |
| freq | 4693 | 26 | 18 | 233 | 48 | 1 | NaN | NaN | 8 | 4 | 1 | 4582 | 3710 | 2067 | NaN |
| mean | NaN | NaN | NaN | NaN | NaN | NaN | 8.264492e+04 | 9579.815907 | NaN | NaN | NaN | NaN | NaN | NaN | 7348.294142 |
| std | NaN | NaN | NaN | NaN | NaN | NaN | 1.383222e+05 | 18164.316990 | NaN | NaN | NaN | NaN | NaN | NaN | 19206.016458 |
| min | NaN | NaN | NaN | NaN | NaN | NaN | 5.000000e+00 | 0.000000 | NaN | NaN | NaN | NaN | NaN | NaN | 0.000000 |
| 25% | NaN | NaN | NaN | NaN | NaN | NaN | 8.361750e+03 | 1394.750000 | NaN | NaN | NaN | NaN | NaN | NaN | 0.000000 |
| 50% | NaN | NaN | NaN | NaN | NaN | NaN | 3.313250e+04 | 3049.000000 | NaN | NaN | NaN | NaN | NaN | NaN | 159.000000 |
| 75% | NaN | NaN | NaN | NaN | NaN | NaN | 9.377275e+04 | 13616.750000 | NaN | NaN | NaN | NaN | NaN | NaN | 2000.000000 |
| max | NaN | NaN | NaN | NaN | NaN | NaN | 1.689764e+06 | 656730.000000 | NaN | NaN | NaN | NaN | NaN | NaN | 349000.000000 |
df.describe(include=['object']).T # DF.T 행과 열을 바꿈
| count | unique | top | freq | |
|---|---|---|---|---|
| color | 4897 | 2 | Color | 4693 |
| director_name | 4814 | 2397 | Steven Spielberg | 26 |
| actor_2_name | 4903 | 3030 | Morgan Freeman | 18 |
| genres | 4916 | 914 | Drama | 233 |
| actor_1_name | 4909 | 2095 | Robert De Niro | 48 |
| movie_title | 4916 | 4916 | Avatar | 1 |
| actor_3_name | 4893 | 3519 | Steve Coogan | 8 |
| plot_keywords | 4764 | 4756 | based on novel | 4 |
| movie_imdb_link | 4916 | 4916 | http://www.imdb.com/title/tt0499549/?ref_=fn_t... | 1 |
| language | 4904 | 47 | English | 4582 |
| country | 4911 | 65 | USA | 3710 |
| content_rating | 4616 | 18 | R | 2067 |
df.mean(numeric_only=None) # 수치형(정수, 실수)
# 핑크색 안내의 의미 - 지금은 정상 가동 가능하지만, 나중에는 문제가 될 수도 있다.
/var/folders/nc/lry6d8ws417_mblykm_8wpc40000gn/T/ipykernel_1183/2254227961.py:1: FutureWarning: The default value of numeric_only in DataFrame.mean is deprecated. In a future version, it will default to False. In addition, specifying 'numeric_only=None' is deprecated. Select only valid columns or specify the value of numeric_only to silence this warning.
df.mean() # 수치형(정수, 실수)
num_critic_for_reviews 1.379889e+02
duration 1.070908e+02
director_facebook_likes 6.910145e+02
actor_3_facebook_likes 6.312763e+02
actor_1_facebook_likes 6.494488e+03
gross 4.764451e+07
num_voted_users 8.264492e+04
cast_total_facebook_likes 9.579816e+03
facenumber_in_poster 1.377320e+00
num_user_for_reviews 2.676688e+02
budget 3.654749e+07
title_year 2.002448e+03
actor_2_facebook_likes 1.621924e+03
imdb_score 6.437429e+00
aspect_ratio 2.222349e+00
movie_facebook_likes 7.348294e+03
dtype: float64
df.mean(numeric_only=True) # 핑크색 안내 내용에 따라 'numeric_only'를 True로 실행하면 정상적으로 구동 확인.
num_critic_for_reviews 1.379889e+02
duration 1.070908e+02
director_facebook_likes 6.910145e+02
actor_3_facebook_likes 6.312763e+02
actor_1_facebook_likes 6.494488e+03
gross 4.764451e+07
num_voted_users 8.264492e+04
cast_total_facebook_likes 9.579816e+03
facenumber_in_poster 1.377320e+00
num_user_for_reviews 2.676688e+02
budget 3.654749e+07
title_year 2.002448e+03
actor_2_facebook_likes 1.621924e+03
imdb_score 6.437429e+00
aspect_ratio 2.222349e+00
movie_facebook_likes 7.348294e+03
dtype: float64
컬럼이름/행이름 조회 및 변경
컬럼이름/행이름 조회
- DataFrame객체.columns
- 컬럼명 조회
- 컬럼명은 차후 조회를 위해 따로 변수에 저장하는 것이 좋다.
- DataFrame객체.index
- 행명 조회
movie.columns
Index(['color', 'director_name', 'num_critic_for_reviews', 'duration',
'director_facebook_likes', 'actor_3_facebook_likes', 'actor_2_name',
'actor_1_facebook_likes', 'gross', 'genres', 'actor_1_name',
'movie_title', 'num_voted_users', 'cast_total_facebook_likes',
'actor_3_name', 'facenumber_in_poster', 'plot_keywords',
'movie_imdb_link', 'num_user_for_reviews', 'language', 'country',
'content_rating', 'budget', 'title_year', 'actor_2_facebook_likes',
'imdb_score', 'aspect_ratio', 'movie_facebook_likes'],
dtype='object')
movie.index
RangeIndex(start=0, stop=4916, step=1)
movie.columns[3]
movie.columns[3:10]
Index(['duration', 'director_facebook_likes', 'actor_3_facebook_likes',
'actor_2_name', 'actor_1_facebook_likes', 'gross', 'genres'],
dtype='object')
컬럼이름/행이름 변경
- columns와 index 속성으로는 통째로 바꾸는 것은 가능하나 일부만 선택해서 변경하는 것은 안된다.
df.columns = ['새이름','새이름', ... , '새이름']df.columns[1] = '새이름'- 이런식으로 개별적으로 변경은 안된다.
dic = {
'id':['id-1', 'id-2', 'id-3', 'id-4', 'id-5'],
'국어':[100,50,70,60,90],
'영어':[90,80,100,60,40]
}
grade = pd.DataFrame(dic)
grade= pd.read_csv('saved_data/grade2.csv')
grade
| id | korean | english | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
grade.columns
Index(['index', 'ID', 'KOREAN', 'ENGLISH'], dtype='object')
grade.columns = ['ID','국어','영어'] # dataframe 원본이 바뀜.
grade
| ID | 국어 | 영어 | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
grade.columns = ['ID','수학','영어'] # 국어를 수학으로 바꾸는 개별 컬럼 변경은 불가능하다.
# 튜플같은 개념이라 완전히 새로운 dataframe을 만들어야함
컬럼이름/행이름 변경 관련 메소드
DataFrame객체.rename(index=행이름변경설정, columns=열이름변경설정, inplace=False)- 개별 컬럼이름/행이름 변경 하는 메소드
- 변경한 DataFrame을 반환
- 변경설정: 딕셔너리 사용
- {‘기존이름’:’새이름’, ..}
- inplace: 원본을 변경할지 여부(boolean)
# 국어 -> KOREAN, 영어 - > ENGLISH
new_columns = {
'국어': "KOREAN",
'영어': "ENGLISH"
}
new_index = {
# 1:'일',
# 2:'이',
# 3:'삼',
# 4:'사'
}
grade.rename(columns=new_columns, index = new_index, inplace = True) # inplace=True 는 원본 적용(교체).
grade
| ID | KOREAN | ENGLISH | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
컬럼 index 옮기는 명령어.
DataFrame객체.set_index(컬럼이름, inplace=False)- 특정 컬럼을 행의 index 명으로 사용
- 열이 index명이 되면서 그 컬럼은 Data Set 에서 제거된다.
DataFrame객체.reset_index(inplace=False)- index를 첫번째 컬럼으로 복원
# ID를 컬럼을\ 행 식별자(index name) 으로 지정.
grade.set_index('ID', inplace=True)
grade
| KOREAN | ENGLISH | |
|---|---|---|
| ID | ||
| id-1 | 100 | 90 |
| id-2 | 50 | 80 |
| id-3 | 70 | 100 |
| id-4 | 60 | 60 |
| id-5 | 90 | 40 |
grade.to_csv('saved_data/grade7.csv', index = False)
grade2 = pd.read_csv('saved_data/grade7.csv', index_col= 'id')
grade2
| index | korean | english | |
|---|---|---|---|
| id | |||
| id-1 | 0 | 100 | 90 |
| id-2 | 1 | 50 | 80 |
| id-3 | 2 | 70 | 100 |
| id-4 | 3 | 60 | 60 |
| id-5 | 4 | 90 | 40 |
grade.reset_index(inplace = True) # index name을 컬럼으로(값)을 뺀다.\
grade
| ID | KOREAN | ENGLISH | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
grade8 = grade.iloc[[4,2,3,1,0]] # 행조회 (index- 순번-으로 조회)
grade8.reset_index(drop=True) # index 이름을 제거 -> index이름은 순번으로 변경.
| ID | KOREAN | ENGLISH | |
|---|---|---|---|
| 0 | id-5 | 90 | 40 |
| 1 | id-3 | 70 | 100 |
| 2 | id-4 | 60 | 60 |
| 3 | id-2 | 50 | 80 |
| 4 | id-1 | 100 | 90 |
행과 열의 값 변경
특정 행 또는 열 삭제
- DataFrame객체.drop(columns, index, inplace=False)
- columns : 삭제할 열이름 또는 열이름 리스트
- index : 삭제할 index명 또는 index 리스트
- inplace: 원본을 변경할지 여부(boolean)
grade
| id | KOREAN | ENGLISH | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 1 | id-2 | 50 | 80 |
| 2 | id-3 | 70 | 100 |
| 3 | id-4 | 60 | 60 |
| 4 | id-5 | 90 | 40 |
# 컬럼 삭제
grade.drop(columns="KOREAN")
grade.drop(columns=['KOREAN', 'ENGLISH'])
| ID | |
|---|---|
| 0 | id-1 |
| 일 | id-2 |
| 이 | id-3 |
| 삼 | id-4 |
| 사 | id-5 |
# 행 삭제
grade.drop(index='이')
grade.drop(index=['일','이','사'])
| ID | KOREAN | ENGLISH | |
|---|---|---|---|
| 0 | id-1 | 100 | 90 |
| 삼 | id-4 | 60 | 60 |
grade7.drop(index='id-2')
grade7.drop(index=['id-1','id-3'])
| Unnamed: 0 | index | KOREAN | ENGLISH | |
|---|---|---|---|---|
| ID | ||||
| id-2 | 1 | 1 | 50 | 80 |
| id-4 | 3 | 3 | 60 | 60 |
| id-5 | 4 | 4 | 90 | 40 |
grade7.drop(labels='KOREAN',axis=1) #컬럼삭제
| Unnamed: 0 | index | ENGLISH | |
|---|---|---|---|
| ID | |||
| id-1 | 0 | 0 | 90 |
| id-2 | 1 | 1 | 80 |
| id-3 | 2 | 2 | 100 |
| id-4 | 3 | 3 | 60 |
| id-5 | 4 | 4 | 40 |
grade7.drop(labels=['id-3','id-1'], axis=0) #행 삭제
| Unnamed: 0 | index | KOREAN | ENGLISH | |
|---|---|---|---|---|
| ID | ||||
| id-2 | 1 | 1 | 50 | 80 |
| id-4 | 3 | 3 | 60 | 60 |
| id-5 | 4 | 4 | 90 | 40 |
grade.shape # (5,3)중 5는 행 0번축 //// 3은 열 1번축
(5, 3)
열 추가
- 새로운 열을 지정 후 값을 대입하면 새로운 열을 추가할 수 있다.
- 보통 파생변수를 만들 때 사용한다.
- 열 추가
df['새열명'] = 값- 마지막 열로 추가된다.
- 하나의 값을 대입하면 모든 행에 그 값이 대입된다.
- 다른 값을 주려면 배열에 담아서 대입한다.
- 열 삽입
df.insert(삽입할 위치 index, 삽입할 열이름, 값)
- 파생변수생성
- 기존 열들의 값을 이용해서 만든 열을 파생변수라고 한다. ######## 값의 계산으로 얻은 변수
- 벡터화 연산을 이용하여 값 대입한다.
- df[‘새열이름’] = 기존 열들을 이용한 연산
# 컴럼값 조회
# 컬럼값 변경 df['컬럼명'] = 값 (없는 컴러미 추가, 있는 컬럼: 변경)
grade['MATH'] = 90 # 추가
grade
| ID | KOREAN | ENGLISH | MATH | |
|---|---|---|---|---|
| 0 | id-1 | 100 | 90 | 90 |
| 1 | id-2 | 50 | 80 | 90 |
| 2 | id-3 | 70 | 100 | 90 |
| 3 | id-4 | 60 | 60 | 90 |
| 4 | id-5 | 90 | 40 | 90 |
grade['PYTHON'] = [100,20,50,60,40] # 추가
grade
| ID | KOREAN | ENGLISH | MATH | PYTHON | |
|---|---|---|---|---|---|
| 0 | id-1 | 100 | 90 | 90 | 100 |
| 1 | id-2 | 50 | 80 | 90 | 20 |
| 2 | id-3 | 70 | 100 | 90 | 50 |
| 3 | id-4 | 60 | 60 | 90 | 60 |
| 4 | id-5 | 90 | 40 | 90 | 40 |
# 열의 값들을 조회
# 한개 컬럼 조회 -> Series로 변환
grade['KOREAN']
0 100
1 50
2 70
3 60
4 90
Name: KOREAN, dtype: int64
index name ==> 조회 DataFrame의 index name
0 100 => 0행의 KOREAN값 100
1 50
2 70
3 60
4 90
Name: KOREAN, dtype: int64
Name -> 조회한 컬럼.
grade['총점']= grade['KOREAN'] + grade["MATH"] + grade['ENGLISH'] + grade["PYTHON"]
# 같은 index를 갖고있어 연산 가능.
grade['평균'] = grade['총점'] / 4
grade
| ID | KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|---|
| 0 | id-1 | 100 | 90 | 90 | 100 | 380 | 95.0 |
| 1 | id-2 | 50 | 80 | 90 | 20 | 240 | 60.0 |
| 2 | id-3 | 70 | 100 | 90 | 50 | 310 | 77.5 |
| 3 | id-4 | 60 | 60 | 90 | 60 | 270 | 67.5 |
| 4 | id-5 | 90 | 40 | 90 | 40 | 260 | 65.0 |
g = grade.set_index('ID')
g
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100 | 90 | 90 | 100 | 380 | 95.0 |
| id-2 | 50 | 80 | 90 | 20 | 240 | 60.0 |
| id-3 | 70 | 100 | 90 | 50 | 310 | 77.5 |
| id-4 | 60 | 60 | 90 | 60 | 270 | 67.5 |
| id-5 | 90 | 40 | 90 | 40 | 260 | 65.0 |
g2 = g.drop(labels=['총점','평균'], axis = 1)
g2
| KOREAN | ENGLISH | MATH | PYTHON | |
|---|---|---|---|---|
| ID | ||||
| id-1 | 100 | 90 | 90 | 100 |
| id-2 | 50 | 80 | 90 | 20 |
| id-3 | 70 | 100 | 90 | 50 |
| id-4 | 60 | 60 | 90 | 60 |
| id-5 | 90 | 40 | 90 | 40 |
g2.sum() # 각 컬럼의 합의 값이다.
KOREAN 370
ENGLISH 370
MATH 450
PYTHON 270
dtype: int64
total = g2.sum(axis=1) #axis=1 -----------> 이방향으로 계산. 그럼, 한 사람의 총점을 구할 수 있다.
avg = g2.mean(axis=1)
g2['총점'] = total
g2['평균'] = avg
g2
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100 | 90 | 90 | 100 | 380 | 95.0 |
| id-2 | 50 | 80 | 90 | 20 | 240 | 60.0 |
| id-3 | 70 | 100 | 90 | 50 | 310 | 77.5 |
| id-4 | 60 | 60 | 90 | 60 | 270 | 67.5 |
| id-5 | 90 | 40 | 90 | 40 | 260 | 65.0 |
g2.sum()
g2.mean()
KOREAN 74.0
ENGLISH 74.0
MATH 90.0
PYTHON 54.0
총점 292.0
평균 73.0
dtype: float64
# 행 추가
g2.loc['평균'] = g2.mean()
g2
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
| id-3 | 70.0 | 100.0 | 90.0 | 50.0 | 310.0 | 77.5 |
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 | 270.0 | 67.5 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
| 평균 | 74.0 | 74.0 | 90.0 | 54.0 | 292.0 | 73.0 |
# 행조회
g2.loc['id-5'] # 행 이름으로 조회
g2.iloc[4] # 행 순번으로 조회
KOREAN 90.0
ENGLISH 40.0
MATH 90.0
PYTHON 40.0
총점 260.0
평균 65.0
Name: id-5, dtype: float64
행, 열의 값 조회
- indexer 연산자를 이용한다.
- 행은 loc indexer, iloc indexer를 사용한다.
- 열은 indexing만 되고 slicing은 안된다.
- 행은 indexing, slicing 모두 지원한다.
열의 값 조회
- df[‘열이름’]
- 열이름의 열 조회
- df.열이름
- 열이름이 Python 식별자 규칙에 맞으면 . 표기법을 사용할 수 있다.
- Fancy indexing
- 여러개의 열들을 한번에 조회할 경우 열이름들을 리스트로 묶어서 전달한다.
- 주의
- 열은 순번으로는 조회할 수 없다.
- 열 조회 indexer에서 슬라이싱을 하면 행 조회 Slicing이다.
- 만약 indexing이나 slicing을 이용해 열들을 조회하려면 columns 속성을 이용한다.
df[df.columns[:3]]
- 만약 indexing이나 slicing을 이용해 열들을 조회하려면 columns 속성을 이용한다.
g2['KOREAN']
g2.KOREAN
ID
id-1 100.0
id-2 50.0
id-3 70.0
id-4 60.0
id-5 90.0
평균 74.0
Name: KOREAN, dtype: float64
g2['KOREAN'] # 대소문자 구분.
g2[0] # 컬럼 순번으로는 조회할 수 없다.
g2.columns[0]
g2[g2.columns[0]] # 컬럼 순버능로 죄하려면 columns를 이용.
0 id-1
1 id-2
2 id-3
3 id-4
4 id-5
Name: ID, dtype: object
col = g2.columns # g2.columns 입력이 번거러울 시 변수 설정 이후 값 적용.
g2[col[0]]
0 id-1
1 id-2
2 id-3
3 id-4
4 id-5
Name: ID, dtype: object
g2[1:4] # 행 slicing
| ID | KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|---|
| 1 | id-2 | 50 | 80 | 90 | 20 | 240 | 60.0 |
| 2 | id-3 | 70 | 100 | 90 | 50 | 310 | 77.5 |
| 3 | id-4 | 60 | 60 | 90 | 60 | 270 | 67.5 |
다양한 열선택 기능을 제공하는 메소드들
select_dtypes(include=[데이터타입,..], exclude=[데이터타입,..])- 전달한 데이터 타입의 열들을 조회.
- include : 조회할 열 데이터 타입
- exclude : 제외하고 조회할 열 데이터 타입
filter (items=[], like='', regex='')- 매개변수에 전달하는 열의 이름에 따라 조회
- 각 매개변수중 하나만 사용할 수 있다.
- items = [컬럼명들, ..]
- 리스트와 일치하는 열들 조회
- 이름이 일치 하지 않아도 Error 발생안함.
- like = ‘부분일치문자열’
- 전달한 문자열이 들어간 열들 조회
- 부분일치 개념
- regex = ‘정규표현식’
- 정규 표현식을 이용해 열명의 패턴으로 조회
g2.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5 entries, 0 to 4
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 5 non-null object
1 KOREAN 5 non-null int64
2 ENGLISH 5 non-null int64
3 MATH 5 non-null int64
4 PYTHON 5 non-null int64
5 총점 5 non-null int64
6 평균 5 non-null float64
7 Pass 5 non-null bool
8 Pass2 5 non-null object
dtypes: bool(1), float64(1), int64(5), object(2)
memory usage: 365.0+ bytes
# 컬럼(Series)의 data type을 변경
g2['MATH'].astype('int32') # 원본을 바꾸지 않는다 / 단지 조회한 것이다.
0 90
1 90
2 90
3 90
4 90
Name: MATH, dtype: int32
g2.select_dtypes(include= 'float64')
g2.select_dtypes(include= ['float64', 'int32'])
| MATH | 평균 | |
|---|---|---|
| 0 | 90 | 95.0 |
| 1 | 90 | 60.0 |
| 2 | 90 | 77.5 |
| 3 | 90 | 67.5 |
| 4 | 90 | 65.0 |
# 조회대상에서 제외하려는 타입을 지정.
g2.select_dtypes(exclude='int64')
g2.select_dtypes(exclude=['int64','int64'])
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
| id-3 | 70.0 | 100.0 | 90.0 | 50.0 | 310.0 | 77.5 |
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 | 270.0 | 67.5 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
| 평균 | 74.0 | 74.0 | 90.0 | 54.0 | 292.0 | 73.0 |
# filter()
# g2['KOR'] # indexer는 없는 컬럼 조회시 Exception 발생(KeyError)
g2.filter(items='KOR') # 없는 컬럼 조회하면 Exception 발생하지 않고 무시.
g2.filter(items=['KOREAN','ENGLISH','MUSIC','PAINTING'])
| KOREAN | ENGLISH | |
|---|---|---|
| ID | ||
| id-1 | 100.0 | 90.0 |
| id-2 | 50.0 | 80.0 |
| id-3 | 70.0 | 100.0 |
| id-4 | 60.0 | 60.0 |
| id-5 | 90.0 | 40.0 |
| 평균 | 74.0 | 74.0 |
g2.filter(like="PASS") # 컬럼명에 PASS가 들어간 컬럼을 조회.
| ID |
|---|
| id-1 |
| id-2 |
| id-3 |
| id-4 |
| id-5 |
| 평균 |
g2.filter(regex='\w{5,}') # 컬럼명이 5글자 이상인 컬럼들을 조회
| KOREAN | ENGLISH | PYTHON | |
|---|---|---|---|
| ID | |||
| id-1 | 100.0 | 90.0 | 100.0 |
| id-2 | 50.0 | 80.0 | 20.0 |
| id-3 | 70.0 | 100.0 | 50.0 |
| id-4 | 60.0 | 60.0 | 60.0 |
| id-5 | 90.0 | 40.0 | 40.0 |
| 평균 | 74.0 | 74.0 | 54.0 |
행 조회
- loc : index 이름으로 조회
- iloc : 행 순번으로 조회
loc indexer
- index name으로 조회
DF.loc[ index이름 ]- 한 행 조회.
- 조회할 행 index 이름(레이블) 전달
- 이름이 문자열이면 “ “ 문자열표기법으로 전달. 정수이며 정수표기법으로 전달한다.
DF.loc[ index이름 리스트 ]- 여러 행 조회.
- 팬시 인덱스
- 조회할 행 index 이름(레이블) 리스트 전달
DF.loc[start index이름 : end index이름: step]- 슬라이싱 지원
- end index 이름의 행까지 포함한다.
DF.loc[index이름 , 컬럼이름]- 행과 열 조회
- 둘다 이름으로 지정해야 함.
g2
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
| id-3 | 70.0 | 100.0 | 90.0 | 50.0 | 310.0 | 77.5 |
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 | 270.0 | 67.5 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
| 평균 | 74.0 | 74.0 | 90.0 | 54.0 | 292.0 | 73.0 |
g2.loc[1]
"""
id id-2
KOREAN 50
ENGLISH 80
MATH 90
PYTHON 20
총점 240
평균 60.0
Pass False
Pass2 낙제
Name: 1, dtype: object
"""
g2.loc[['id-1','id-2']] # fancy indexing
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
# 행조회는 slicing 지원
g2.loc['id-1':'id-5'] # stop index 도 포함
g2.loc['id-1':'id-5':2]
g2.loc['id-1':] # stop 생략 => 마지막 행까지 다 조회
g2.loc[:'id-2'] # start 생략 => 시작 행(0번 행) 부터 조회
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
# g2.loc[1]['KOREAN']
g2.loc['id-1','KOREAN']
# df.loc[ 행조회, 열조회] == 행/열 모두 이름
100.0
g2.loc[['id-1','id-2','id-4'], '총점'] # 행: fancy indexing, 열: 하나를 지정
g2.loc[['id-1','id-2','id-4'], ['총점', '평균']] # 행: fancy indexing, 열: fancy indexing
g2.loc[['id-1','id-2'],:"PYTHON"] # 행: 하나또는 두개 지정. 열:slicing(loc 에서는 열도 slicing 가능.)
| KOREAN | ENGLISH | MATH | PYTHON | |
|---|---|---|---|---|
| ID | ||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 |
g2.loc[1:3,'ENGLISH':"평균"] # 행/열 모두 slicing
| ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|
| 1 | 80 | 90 | 20 | 240 | 60.0 |
| 2 | 100 | 90 | 50 | 310 | 77.5 |
| 3 | 60 | 90 | 60 | 270 | 67.5 |
g2.loc[1,0] # 컬럼명이 0인 컬럼조회. loc index는 행/열 모두 이름으로 조회. Exception 발생.
iloc
- index(행 순번)으로 조회
DF.iloc[행번호]- 한 행 조회.
- 조회할 행 번호 전달
DF.iloc[ 행번호 리스트 ]- 여러 행 조회.
- 조회할 행 번호 리스트 전달
DF.iloc[start 행번호: stop 행번호: step]- 슬라이싱 지원
- stop 행번호 포함 안함.
DF.iloc[행번호 , 열번호]- 행과 열 조회
- 행열 모두 순번으로 지정
# g2[2] # 컬럼이 이름이 2인 열을 조회
g2.loc['id-2'] #행(index)이름이 2인 행을 조회
g2.iloc[2] #index(순번) 이름이 2인 행을 조회
KOREAN 70.0
ENGLISH 100.0
MATH 90.0
PYTHON 50.0
총점 310.0
평균 77.5
Name: id-3, dtype: float64
g2.iloc[[2,1,4]] #fancy indexing : list 순번으로 조회
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-3 | 70.0 | 100.0 | 90.0 | 50.0 | 310.0 | 77.5 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
g2.iloc[-3:] # 뒤에서 3번쨰 행 ~ 끝까지
g2.tail(3) # 위에 명령어랑 같음.
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 | 270.0 | 67.5 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
| 평균 | 74.0 | 74.0 | 90.0 | 54.0 | 292.0 | 73.0 |
g2.iloc[::-1] # 리버스
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| 평균 | 74.0 | 74.0 | 90.0 | 54.0 | 292.0 | 73.0 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 | 270.0 | 67.5 |
| id-3 | 70.0 | 100.0 | 90.0 | 50.0 | 310.0 | 77.5 |
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 | 240.0 | 60.0 |
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
# g2.iloc[3,"ENGLISH"] => iloc [행 순번, 열 순번] 으로 해야함.
# 둘다 수넙능ㄹ 이용해서 지정 (indexing slcing, facy indexing 문법 사용가능)
g2.iloc[3, 1]
g2.iloc[[1,3],[2,5]] # 열 2번 5번
g2.iloc[[1,3],:4] # 열 0 ~ 3번(4번은 포함하지 않음)
| KOREAN | ENGLISH | MATH | PYTHON | |
|---|---|---|---|---|
| ID | ||||
| id-2 | 50.0 | 80.0 | 90.0 | 20.0 |
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 |
Boolean indexing을 이용한 조회
-
원하는 조건을 만족하는 행, 열을 조회한다.
DataFrame객체[조건], DataFrame객체.loc[조건]- 조건이 True인 행만 조회
- 열까지 선택시
DataFrame객체[조건][열]DataFrame객체.loc[조건, 열]
- iloc indexer는 boolean indexing을 지원하지 않는다.
- 논리연산자 |논리연산자|설명| |:-:|-| |&|and연산| |||or연산| |~|not 연산|
- 논리연산자의 피연산자들은 반드시 ( )로 묶어준다.
- 파이썬과는 다르게
and,or,not예약어는 사용할 수 없다.
# 국어점수가 80이상인 행을 조회
g2[g2['KOREAN'] >= 80]
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-1 | 100.0 | 90.0 | 90.0 | 100.0 | 380.0 | 95.0 |
| id-5 | 90.0 | 40.0 | 90.0 | 40.0 | 260.0 | 65.0 |
# 국어가 60~80 사이인 행들
g2[(g2['KOREAN'] >= 60) & (g2['KOREAN'] <=80)]
g2[g2['KOREAN'].between(60,80)]
| KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| id-3 | 70.0 | 100.0 | 90.0 | 50.0 | 310.0 | 77.5 |
| id-4 | 60.0 | 60.0 | 90.0 | 60.0 | 270.0 | 67.5 |
| 평균 | 74.0 | 74.0 | 90.0 | 54.0 | 292.0 | 73.0 |
# 국어가 60~80 사이이고 영어가 100점인 행들
g2[(g2['KOREAN'] >= 60) & (g2['KOREAN'] <=80) & (g2['ENGLISH'] == 100)]
| id | KOREAN | ENGLISH | MATH | PYTHON | 총점 | 평균 | Pass | Pass2 | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | id-3 | 70 | 100 | 90 | 50 | 310 | 77.5 | False | 낙제 |
# 국어가 60~80 사이이고 영어가 100점인 행들의 국어, 영어, 평균점수를 확인
g2[(g2['KOREAN'] >= 60) & (g2['KOREAN'] <=80) & (g2['ENGLISH'] == 100)][['KOREAN', "ENGLISH", "평균"]]
| KOREAN | ENGLISH | 평균 | |
|---|---|---|---|
| ID | |||
| id-3 | 70.0 | 100.0 | 77.5 |
g2[g2['KOREAN'].between(60,80) & (g2['ENGLISH'] ==100)][['KOREAN', "ENGLISH", "평균"]]
| KOREAN | ENGLISH | 평균 | |
|---|---|---|---|
| ID | |||
| id-3 | 70.0 | 100.0 | 77.5 |
# df.loc [행 -> boolen index, 열]
g2.loc[g2['KOREAN'].between(60,80) & (g2['ENGLISH'] ==100), ['KOREAN', "ENGLISH", "평균"]]
| KOREAN | ENGLISH | 평균 | |
|---|---|---|---|
| ID | |||
| id-3 | 70.0 | 100.0 | 77.5 |
query() 를 이용한 boolean indexing
- query(조회조건)
- sql의 where 절의 조건 처럼 문자열의 query statement를 이용해 조건으로 조회
- boolean index에 비해
- 장점: 편의성(문자열로 query statement를 만들므로 동적 구문 생성등 다양한 처리가 가능)과 가독성이 좋다.
- 단점: 속도가 느리다.
- 조회조건 구문
"컬럼명 연산자 비교값"
- 외부변수를 이용해 query문의 비교값을 지정할 수 있다.
- query 문자열 안에서 @변수명 사용
- f string이나 format() 함수를 이용해 query를 만들 수도 있다.
query 함수 연산자
- 비교 연산자
- ==, >, >=, <, <=, !=
- 결측치 비교
- 컬럼.isna(), isnull()
- 컬럼.notna(), notnull()
- 논리 연산자
- and, or, not
- in 연산자
- in, ==
- not in, !=
- 비교 대상값은 리스트에 넣는다.
- Index name으로 검색
- 행의 index 이름으로 검색
- 문자열 부분검색(sql의 like)
- 컬럼명.str.contains(문자열): 문자열을 포함하고 있는
- 컬럼명.str.startswith(문자열): 문자열로 시작하는
- 컬럼명.str.endswith(문자열): 문자열로 끝나는
- 문자열 부분검색을 할 컬럼에 결측치(NaN)이 있으면 안된다.
import pandas as pd
import numpy as np
data_dict = {
'name':['김영수', '박영희', '오준호', '조민경', '박영희', '김영수'],
'age':[23, 17, 28, 31, 23, 17],
'email':['s@gmail.com', 'pyh@gmail.com', 'ojh@daum.net', 'cmk@naver.com', 'pyh@daum.net', np.nan]
}
df = pd.DataFrame(data_dict)
df
| name | age | ||
|---|---|---|---|
| 0 | 김영수 | 23 | s@gmail.com |
| 1 | 박영희 | 17 | pyh@gmail.com |
| 2 | 오준호 | 28 | ojh@daum.net |
| 3 | 조민경 | 31 | cmk@naver.com |
| 4 | 박영희 | 23 | pyh@daum.net |
| 5 | 김영수 | 17 | NaN |
# 비교연산
# 나이가 17세인 사람
# df[df['age'] == 17]
df.query('age==17') # 조회대상데이터프레임.query('컬럼명 == 비교값')
df.query('age>25')
df.query('age!=17')
| name | age | ||
|---|---|---|---|
| 0 | 김영수 | 23 | kys@gmail.com |
| 2 | 오준호 | 28 | ojh@daum.net |
| 3 | 조민경 | 31 | cmk@naver.com |
| 4 | 박영희 | 23 | pyh@daum.net |
# 결측치가 있는 행
df.query('email.isna()') # 대상컬럼.isnull(),isna()
df.query('email.isnull()')
| name | age | ||
|---|---|---|---|
| 5 | 김영수 | 17 | NaN |
# 결측치가 없는 행
df.query('email.notna()')
df.query('email.notnull()')
| name | age | ||
|---|---|---|---|
| 0 | 김영수 | 23 | kys@gmail.com |
| 1 | 박영희 | 17 | pyh@gmail.com |
| 2 | 오준호 | 28 | ojh@daum.net |
| 3 | 조민경 | 31 | cmk@naver.com |
| 4 | 박영희 | 23 | pyh@daum.net |
# 논리연산 -> and, or, not 을 사용가능. (&,|, ~ 사용가능.)
df.query('not age<25')
df.query('~(age<25)')
| name | age | ||
|---|---|---|---|
| 2 | 오준호 | 28 | ojh@daum.net |
| 3 | 조민경 | 31 | cmk@naver.com |
df.query('name=="박영희" and age>20') # 비교값이 문자열(str) 일때는 따옴표로 묶어준다.
df.query('(name=="박영희") & (age>20)') # query 메소드에서는 기로 비교연산을 할때 ()로 피연산자 안묶어도 된다.
| name | age | ||
|---|---|---|---|
| 4 | 박영희 | 23 | pyh@daum.net |
# 나이가 17 이거나 23인 행을 조회
df.query('age==17 or age==23') # 동일한 컬럼으로 여러개의 값과 == 비교.
df.query('age == [17,23]')
df.query('age in [17,23]')
| name | age | ||
|---|---|---|---|
| 0 | 김영수 | 23 | kys@gmail.com |
| 1 | 박영희 | 17 | pyh@gmail.com |
| 4 | 박영희 | 23 | pyh@daum.net |
| 5 | 김영수 | 17 | NaN |
# 나이가 17 이거나 23이 아닌 행을 조회
df.query('age!=17 and age!=23') # 동일한 컬럼으로 여러개의 값과 == 비교.
df.query('age != [17,23]')
df.query('age not in [17,23]')
| name | age | ||
|---|---|---|---|
| 2 | 오준호 | 28 | ojh@daum.net |
| 3 | 조민경 | 31 | cmk@naver.com |
# index 이름으로 조건 지정. ==> index 키워드 사용.
# index 이름이 3인 행을 조회
df.query('index == 3') # 데이터프레임으로 반환
| name | age | ||
|---|---|---|---|
| 3 | 조민경 | 31 | cmk@naver.com |
df.query('index in [1,3,4]')
| name | age | ||
|---|---|---|---|
| 1 | 박영희 | 17 | pyh@gmail.com |
| 3 | 조민경 | 31 | cmk@naver.com |
| 4 | 박영희 | 23 | pyh@daum.net |
# 문자열컬럼값과 부분 일치 조회
# 성이 김씨인 행 조회
df.query('name.str.startswith("김")') # name 컬럼의 값들 중 '김'으로 시작하는 행
| name | age | ||
|---|---|---|---|
| 0 | 김영수 | 23 | kys@gmail.com |
| 5 | 김영수 | 17 | NaN |
# 이름이 영희 행을 조회
df.query('name.str.endswith("영희")') # name 컬럼의 값들 중 '영희' 로 끝나는 행
df.query('name.str.contains("영희")') # name 컬럼의 값들 중 '영희' 를 포함한 행
| name | age | ||
|---|---|---|---|
| 1 | 박영희 | 17 | pyh@gmail.com |
| 4 | 박영희 | 23 | pyh@daum.net |
# 이메일주소가 com으로 끝나는 행들
# 문자열 부분일치 조회 -> 결측치가 있는 행은 조회가 힘듬(ValueError 발생)
df.query('email.str.endswith("com")')
# 1. email이 결측치가 아닌 행을 조회 -> 2. 조건을 조회
df.query('email.notnull()').query('email.str.endswith("com")')
# (메소드, 함수)chaining - 계속 연결해서 처리 진행.
| name | age | ||
|---|---|---|---|
| 0 | 김영수 | 23 | kys@gmail.com |
| 1 | 박영희 | 17 | pyh@gmail.com |
| 3 | 조민경 | 31 | cmk@naver.com |
# 외부변수의 값을 이용해서 query statement를 생성.
name = input('조회할 이름:')
#format 문자열
# df.query(f'name == "{name}"')
df.query('name == @name') # name == 변수_name의 값 ==> 문자열일 경우 따음표 처리를 해준다.
조회할 이름:박영희
| name | age | ||
|---|---|---|---|
| 1 | 박영희 | 17 | pyh@gmail.com |
| 4 | 박영희 | 23 | pyh@daum.net |
name = input('조회할 이름:')
age = int(input('조회할 나이:')) # 숫자형은 숫자(정수, 실수) 타입으로 변환 한 뒤 처리.
df.query('name == @name and age > @age')
조회할 이름:박영희
조회할 나이:20
| name | age | ||
|---|---|---|---|
| 4 | 박영희 | 23 | pyh@daum.net |

댓글남기기