- NumPy 개요 및 배열 생성
넘파이 (NumPy)
- http://www.numpy.org
- Numerical Python (숫자를 다루는 파이썬)
- 벡터, 행렬 연산을 위한 수치해석용 파이썬 라이브러리
- 강력한 다차원 배열(array) 지원
- 빠른 수치 계산을 위한 structured array, 벡터화 연산(벡터연산 지원), 브로드캐스팅 기법등을 통한 다차원 배열과 행렬연산에 필요한 다양한 함수를 제공한다.
- 파이썬 List 보다 더 많은 데이터를 더 빠르게 처리
- 많은 과학 연산 라이브러리들이 Numpy를 기반으로 한다.
- scipy, matplotlib, pandas, scikit-learn, statsmodels등
- 선형대수, 난수 생성, 푸리에 변환 기능 지원
넘파이에서 데이터 구조
- 스칼라 (Scalar)
- 값 하나.
- 벡터 (Vector)
- 여러개의 값들을 순서대로 모아놓은 데이터 모음(데이터 레코드)
- 1D Tensor, 1D Array (1차원 배열)
- 행렬 (Matrix)
- 벡터들을 모아놓은 데이터 집합. 2개의 방향으로 값들이 관리된다.
- 2D Tensor, 2D Array (2차원 배열)
- 텐서 (Tensor)
- 같은 크기의 행렬들(텐서들)을 모아놓은 데이터 집합. N개의 방향으로 값들이 관리된다.
- ND Tensor, ND Array (다차원 배열)
- 스칼라 : 0 => 값 하나
- 백터는 : [0, 0, 0, 0, 0, 0] => 1차원 배열
- 행렬 : 2차원 배열 [0, 0, 0, 0, 0, 0] [0, 0, 0, 0, 0, 0] [0, 0, 0, 0, 0, 0]
- 텐서 : 행렬들은 모아놓은 다차원 배열
용어
- 축 (axis)
- 값들의 나열 방향
- 하나의 축(axis)는 하나의 범주(분류, Category)이다.
- 랭크 (rank)
- 데이터 집합에서 축의 개수.
- 차원 (dimension) 이라고도 한다.
- 형태/형상 (shape)
- 각 축(axis) 별 데이터의 개수
- 크기 (size)
- 배열내 원소의 총 개수
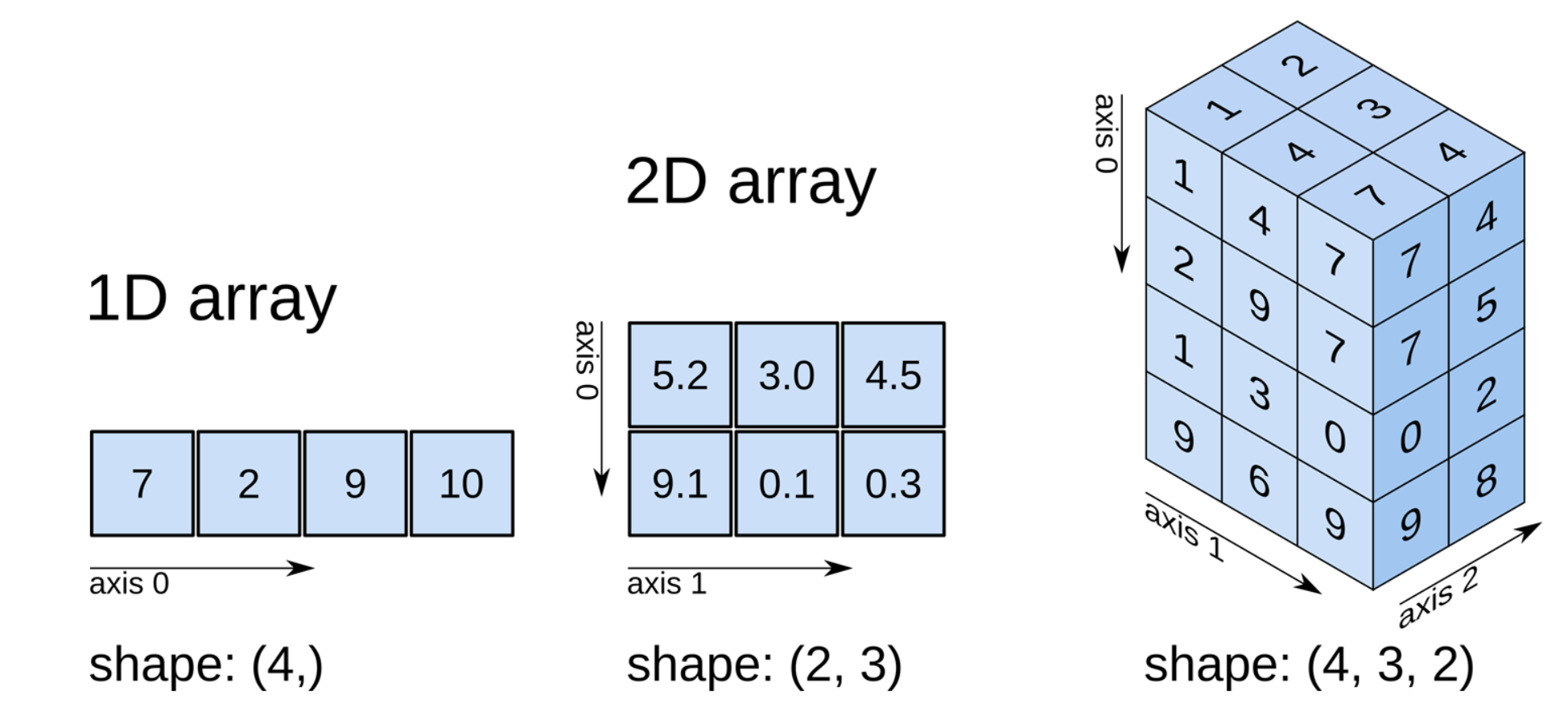
[출처: https://www.oreilly.com/library/view/elegant-scipy/9781491922927/ch01.html ]
( 4 , ) : 값이 4개가 있는 1차원 배열이다.
( 2 , 3 ) : 값이 6개가 있는 2차원 배열이다.
( 4 , 3 , 2 ) : 값이 24개가 있는 3차원 배열이다.
넘파이 배열(ndarray)
- Numpy에서 제공하는 N 차원 배열 객체
- 같은 타입의 값들만 가질 수 있다.
- 축(Axis)별 데이터의 개수는 모두 동일하다.
- 빠르고 메모리를 효율적으로 사용하며 벡터 연산과 브로드캐스팅 기능을 제공한다.
차원 (dimension)
- Vector에서 차원: 원소의 개수
- 넘파이 배열에서 차원: 축의 개수
배열 생성 함수
array(배열형태 객체 [, dtype])
- 배열형태 객체가 가진 원소들로 구성된 numpy 배열 생성
- 원하는 값들로 구성된 배열을 만들때 사용한다.
- 다차원(2차원이상) 배열을 만들 경우 각 axis(축)의 size(데이터의 개수)가 동일하도록 한다.
- 배열형태 객체 (array-like)
- 리스트, 튜플, 넘파이배열(ndarray), Series
### 데이터 타입
- 원소들의 데이터 타입
- ndarray 는 같은 타입의 데이터만 모아서 관리한다.
- 배열 생성시 dtype 속성을 이용해 데이터 타입 설정 가능
- ndarray.dtype 속성을 이용해 조회 - ndarray.astype(데이터타입)
- 데이터타입 변환하는 메소드
- 변환한 새로운 ndarray객체를 반환
- 데이터 타입
- 문자열과 numpy 모듈에서 제공하는 변수를 통해 지정할 수 있다.
| 분류 | 문자열 | numpy 변수 |
|---|---|---|
| 정수형 | “int8” | np.int8 |
| “int16” | np.int16 | |
| “int32” | np.int32 | |
| “int64” | np.int64 | |
| 부호없는정수형 | “uint8” | np.uint8 |
| “uint16” | np.uint16 | |
| “uint32” | np.int32 | |
| “uint64” | np.uint64 | |
| 실수형 | “float16” | np.float16 |
| “float32” | np.float32 | |
| “float64” | np.float64 | |
| 논리형 | “bool” | np.bool |
| 문자열 | “str” | np.str |
Numpy Datatype
- 부호없는 정수형은 양수만 해당된다.
- 정수형은 양수 음수 둘다 해당된다.
- Uint를 사용하는 경우는 영상데이터에 사용된다.(양수만 사용)
* 보통 size를 입력하는것 보다 shape을 입력하는 경우가 더 많다.
- 정수를 읽을 수 있는 크기.
- 8비트: ~128 ~127,
- 16비트 : ~3만 5천 ~ + 3만 5천,
- 32비트: ~21억 ~ +21억,
- 64비트: ~9경 ~ +9경
동일한 값들로 구성된 배열 생성
zeros(shape [, dtype])
영벡터 생성 : 원소들을 0으로 채운 배열
- shape : 형태 지정
- 정수: 1차원일 경우 원소의 개수를 지정
- 튜플: 다차원 배열의 각 축별 size를 설정
- dtype : 데이터타입 지정(생략시 float64)
ones(shape [,dtype])
일벡터 생성 : 원소들을 1로 채운 배열을 생성
- shape : 형태 지정
- 정수: 1차원일 경우 원소의 개수를 지정
- 튜플: 다차원 배열의 각 축별 size를 설정
- dtype : 데이터타입 지정(생략시 float64)
full(shape, fill_value [, dtype])
원소들을 원하는 값으로 채운 배열 생성
- shape : 형태 지정
- 정수: 1차원일 경우 원소의 개수를 지정
- 튜플: 다차원 배열의 각 축별 size를 설정
- fill_vlaue : 채울 값
- dtype : 데이터타입 지정(생략시 float64)
zeros_like(ndarray), ones_like(ndarray), full_like(ndarray, fill_value)
- 매개변수로 받은 배열과 같은 shape의 배열을 생성한다.
# a4 = np.full(shape = (3, 4), fill_value = 'aaa') # dtype은 생략시 값에 맞춰서 설정한다.
a4 = np.full(shape = (3, 4), fill_value = 5.2)
print(a4.shape, a4.dtype)
a4 # '<U1' 은 문자열이다.
(3, 4) float64
array([[5.2, 5.2, 5.2, 5.2],
[5.2, 5.2, 5.2, 5.2],
[5.2, 5.2, 5.2, 5.2]])
특정 범위내에서 동일한 간격의 값들로 구성된 배열생성
arange(start, stop, step, dtype)
start에서 stop 범위에서 step의 일정한 간격의 값들로 구성된 배열 리턴. 1차원 배열만 생성할 수 있다.
- API
- start : 범위의 시작값으로 포함된다.(생략가능 - 기본값:0)
- stop : 범위의 끝값으로 포함되지 않는다. (필수)
- step : 간격 (기본값 1) // 0.1같은 실수도 가능!!
- dtype : 요소의 타입
- 1차원 배열만 생성가능
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
시작과 끝을 균등하게 나눈 값들을 가지는 배열을 생성
등분하는 함수인데 끝을 포함한다.
- start : 시작값
- stop : 종료값
- num : 나눌 개수. 기본-50, 양수 여야한다.
- endpoint : stop을 포함시킬 것인지 여부. 기본 True
- retstep : 생성된 배열 샘플과 함께 간격(step)도 리턴할지 여부. True일경우 간격도 리턴(sample, step) => 튜플로 받는다.
- dtype : 데이터 타입
- 1차원 배열만 생성가능
import matplotlib.pyplot as plt
plt.plot(x,y)
plt.show()
난수(Random value)를 원소로 하는 ndarray 생성
- numpy의 서브패키지인 random 패키지에서 제공하는 함수들을 이용해 생성
np.random.seed(0)
np.random.randint(1,100, size = (4,5)) # 시드값으로 인해 나오는 난수의 출력값은 순서가 있다!! //
array([[80, 5, 43, 59, 32],
[ 2, 66, 42, 58, 36],
[12, 47, 83, 92, 1],
[15, 54, 13, 43, 85]])
이해 도와주기.
- 머신러닝 알고리즘은 이 난수를 이용하는 것들이 많다.
- 머신러닝 알고리즘 개발할때 난수를 넣고 돌린다.
- 성능이 50점이 나와 개선이 필요하다.
- 100점이 나오기 위해 알고리즘을 개선시켜야 한다.
- 그래서 난수를 하나의 기준으로 정한다.
- 알고리즘을 개선 시켰다. 그것을 알기 위해선 똑같은 입력값이 필요하기 때문이다.
- seed 값을 자주 사용한다.
np.random.seed(시드값)
- 난수 발생 알고리즘이 사용할 시작값(시드값)을 설정
- 시드값을 설정하면 항상 일정한 순서의 난수(random value)가 발생한다.
랜덤함수는 특정숫자부터 시작하는 일렬의 수열을 만들어 값을 제공하는 함수이다.
시작 숫자는 실행할때 마다 바뀌므로 다른 값들이 나오는데 시드값은 시작값을 고정시키면 항상 시작 값이 같으므로 같은 값들이 순서대로 제공된다.
매번 실행할때 마다 같은 순서의 임의의 값이(난수) 나오도록 할때 시드값을 설정한다.
np.random.rand([axis0, axis1, axis2, …])
- API
- 0~1사이의 실수를 리턴 (float64)
- 축의 크기는 순서대로 나열한다.
np.random.rand()
np.random.rand(5) # 원소가 5개인 1차원 배열
np.random.rand(3, 2) # (3, 2) 2차원 배열
np.random.rand(3, 4, 2) # (3, 4, 2) 3차원 배열
array([[[0.10286336, 0.09237389],
[0.35404666, 0.55181626],
[0.03362509, 0.96896177],
[0.32099724, 0.22126269]],
[[0.1412639 , 0.09725993],
[0.98404224, 0.26034093],
[0.53702252, 0.44792617],
[0.09956909, 0.35231166]],
[[0.46924917, 0.84114013],
[0.90464774, 0.03755938],
[0.50831545, 0.16684751],
[0.77905102, 0.8649333 ]]])
np.random.normal(loc=0.0, scale=1.0, size=None)
- 정규분포를 따르는 난수. => 평균 과 표준편차로 값이 정해진다.
- API
- loc: 평균
- scale: 표준편차
- loc, scale 생략시 표준정규 분포를 따르는 난수를 제공
정규분포
- 평균: 데이터셋의 값들을 대표하는 값중 하나로 모두 더해서 개수로 나눈 것.
- 정규분포에서 값들이 가장 많이 있을 것이라 생각되는 값이 평균이므로 대푯값으로 사용한다.
- 편차: 데이터셋의 각 값들이 평균과 얼마나 차이가 있는지
- 표준편차: 편차의 평균 (평균으로 부터 각 값들이 얼마나 떨어져 있는지에 대한 평균)
- 분산: 표준편차의 제곱으로 표준편차 계산시 나오는 값.
- 분포: 값이 흩어져 있는 상태를 말한다.
- 정규분포
- 연속 확률 분포중 하나. 우리생활에서 가장 많이 나오는 분포중 하나로 종모양을 하고 있으며 평균근처에 가장 많은 값들이 모여 있고 평균으로 부터 표준편차 많큼 멀어질 수록 적게 분포된다.
- 정규분포에서는 1표준편차 범위의 전체 데이터의 68%가 2표준편차 범위에 전체 데이터의 95% 정도가 분포한다. (3표준편차범위에 약 99.7%가 분포)
- 표준정규분포
- 평균 : 0, 표준편차 : 1 인 정규 분포
- 정규분포는 평균과 표준편차로 표현한다.
- 평균:0 , 표준편차:1 ===> 표준 정규 분포 (2표준편차 범위(평균 - 2표준편차 ~ 평균 + 2표준편차) => 95%)
a = np.random.normal()
# 평균:0 , 표준편차:1 ===> 표준 정규 분포 (2표준편차 범위(평균 - 2*표준편차 ~ 평균 + 2*표준편차) => 95%)
a
-1.0619793207360517
a2 = np.random.normal(100,20) # 60 ~ 140(95%)
a2
62.85825123844198
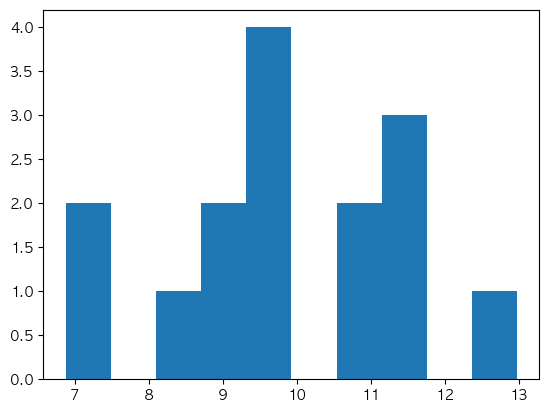
a3 = np.random.normal(10, 2, size = (5,3)) # 8 ~ 12(70%), 6 ~ 14(95%) 나옴.
print(a3.shape)
a3
(5, 3)
array([[10.58671464, 12.97451495, 8.7230402 ],
[11.41753767, 9.83494457, 8.62523253],
[ 7.17737684, 11.24276741, 10.61702247],
[ 9.33812127, 9.02956773, 9.87957636],
[ 6.88070615, 9.41718934, 11.60814385]])
plt.hist(a3.flatten())
plt.show()
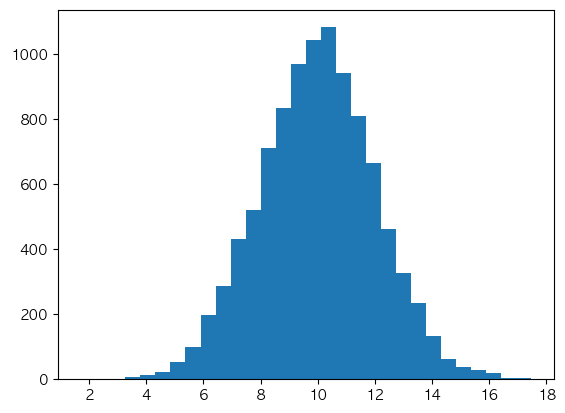
plt.hist(np.random.normal(10, 2, size = 10000), bins = 30)
plt.show()
np.random.randint(low, high=None, size=None, dtype=’int32’)
임의의 정수를 가지는 배열
- API
- low ~ high 사이의 정수 리턴. high는 포함안됨
- high 생략시 0 ~ low 사이 정수 리턴. low는 포함안됨
- size : 배열의 크기. 다차원은 튜플로 지정 기본 1개
- dtype : 원소의 타입
np.random.randint(-10, 10, size = (2, 3, 4)) # (2, 3, 4)
array([[[ -6, -9, 4, 6],
[-10, -9, 5, 4],
[ 3, 7, -10, -8]],
[[ 9, 8, -2, -10],
[ 5, 3, 4, 8],
[ 0, -6, -2, -9]]])
np.random.choice(a, size=None, replace=True, p=None)
- API
- 샘플링(표본추출) 메소드
- a : 샘플링대상. 1차원 배열 또는 정수 (정수일 경우 0 ~ 정수, 정수 불포함)
- size : 샘플 개수
- replace : True-복원추출(기본), False-비복원추출
- p: 샘플링할 대상 값들이 추출될 확률 지정한 배열
- 복원추출: 중복 추출이다.
- 비복원추출: 한번 추출한건 끝이다.
- 많이 사용함
np.random.choice([1,2,3], size = 10, replace = False)
# (3, 2)
# 중복 추출이 안됨( replace = False) ==> 비복원추출 // 모수의 size 초과 추출 안됨.
a = np.random.choice([True, False], size = (5, 5), p = [0.9, 0.1]) # p - 각 값이 나올 확률을 지정. 0.x 합이 1
a
array([[ True, True, True, True, True],
[ True, True, False, True, False],
[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
np.unique(a, return_counts = True) # s.value_counts() 같은 것.
(array([False, True]), array([ 2, 23]))

댓글남기기